The Incubator Lab fosters novel data science developments for ESS in dedicated focused projects. The objective of this task is to steer the exploration of new, potentially relevant building blocks to be included in NFDI4Earth and related NFDIs. Examples are tools for automatic metadata extraction and annotation, semantic mapping and harmonization, machine learning, data fusion, visualization, and interaction. The Incubator Lab also serves as a forum where novel requirements can be formulated and trends presented in terms of a user consultation process. In this way, scouting for new trends and opportunities is achieved. The forum will materialize in annual meetings of NFDI4Earth-Experiment, where both achievements will be presented (e.g. from Lab projects but also from Pilots) and demands will be formulated (e.g. from the participants) which will trigger new ideas and potential projects. The results of the projects as well as the consultation process will be continuously monitored, evaluated and updated, resulting in a living document that describes current and future trends and records their implementation. The measure lead must oversee and monitor that compliance rules concerning the software and infrastructural developments are fulfilled while at the same time innovative blue sky developments should also be encouraged.
Domain: Astrophysics
Contact: Bernhard Haas – GFZ German Research Centre for Geosciences, Potsdam
Email:  bhaas@gfz-potsdam.deI
bhaas@gfz-potsdam.deI
Duration: 4 months
We propose a new Python package for processing satellite data of particle measurements in Earth’s magnetosphere. While most particle measurements of the radiation belts are openly available, they still must be processed (which may include time binning, calculation of equatorial pitch angles and invariants, converting flux to phase space density, etc) to be used in publications. Currently, each research group processes data individually without a standard procedure, making published data challenging to reproduce. An open, easy-to-use package would help new students handle the data and reproduce previous results.
Domain: Atmospheric Science, Oceanography and Climate Research
Contact: Yu Feng. TU München, Lina Hörl.
Bavarian
State Archives (GDA)
Email: y.feng@tum.de
Duration: 6 months
Phenological data, especially long-term data, is crucial for understanding the impact of climate change. However, due to the lack of digitization, comprehensive phenological data from before the 20th century is highly incomplete, hindering long-term climate and ecological research and leaving this area underrepresented in Earth System Science (ESS). The innovation of this project lies in developing an interactive tool called PhenoMapping, which helps digitize and geocode historical records and matches the priorities of scientists’ demands and historians’ capacity through an online platform. It encourages volunteers’ contributions and also allows public users to explore phenological trends from decades and centuries ago. Using an archive collection from 1856 with 7,000 phenological observations as an example, we can demonstrate the value of this tool. Expected outputs include web-based data visualization and transcription tools, along with the acknowledgement of data contributions to existing phenological databases. The expertise of both teams, GDA in handling historical documents and TUM in geospatial data visualization, will support the project’s goal of bridging historical and modern phenological data for ESS research.
Domain: Geography
Contact: Eftychia Koukouraki.
University
of Münster
Email: eftychia.koukouraki@uni-muenster.de
Duration: 6 months
Visual question-answering (QA) helps users interpret complex visual information, making it easier and faster to gain insights also from maps and geospatial data in a variety of contexts. This project aims to create an open dataset tailored for thematic map-based QA systems, accompanied by a baseline model to demonstrate its usage. By compiling map images annotated with question-answer pairs, the dataset will enable Artificial Intelligence (AI) models to extract and interpret geographic and information from maps. The deliverables will include a curated dataset, a baseline model, documentation, and an evaluation report, all of which will be released under a permissive license to support further research on the topic.
ProposalDomain: Atmospheric Science, Oceanography and Climate Research
Contact: Christoph Lorenz, Karlsruhe Institute of Technology
Email: Christof.Lorenz@kit.edu
Cooperators: Barbara Magagna (GO FAIR Foundation, Leiden, Netherlands), Arvin Rastegar, Christof
Lorenz, Christian Chwala (Karlsruhe Institute of Technology – Institute for Meteorology and
Climate Research, Garmisch-Partenkirchen, Germany)
Duration: 6 months
Researchers annotate data with keywords for describing the physical properties that are observed or modeled. For ensuring findability and interoperability of this metadata, the keywords should be machine-readable and adhere to standardized vocabularies or ontologies. The I-ADOPT framework provides guidelines for expressing such keywords in alignment with the FAIR principles; however, transforming commonly used terms into atomic I-ADOPT components remains a highly manual task requiring both semantic and domain expertise. In response, we propose an LLM-based workflow to generate FAIR-compliant descriptions of variables that align with the I-ADOPT Framework.
Domain: Physische
Geographie
Contact: Marco Otto, Technische Universität Berlin
Email:
marco.otto@tu-berlin.de
Duration: 6 months
The project aims to develop a web application, MaRESS (Mapping Research in Earth System Sciences), designed to map research data from peer-reviewed literature to help researchers identify thematic research gaps and geographic knowledge voids. MaRESS will support researchers in formulating targeted questions and objectives within Earth System Sciences (ESS), advancing scientific understanding across ESS by providing a structured framework to build specific knowledge bases. Using a modular design, MaRESS will integrate geographic data (“geographic mapping”), an open-access reference management tool for knowledge organization (“semantic mapping”), support for data integration (“data mapping”), and AI-assisted categorization. These components will enhance data accessibility and information management for all research areas within ESS. The software will be portable and deployable using containerization (e.g., Docker or LXC) and will include comprehensive documentation, supporting FAIR data principles and facilitating open access. Initially, MaRESS will be applied to an existing knowledge base on High Mountain Wetlands, with potential for global expansion as additional regions and datasets are incorporated.
Proposal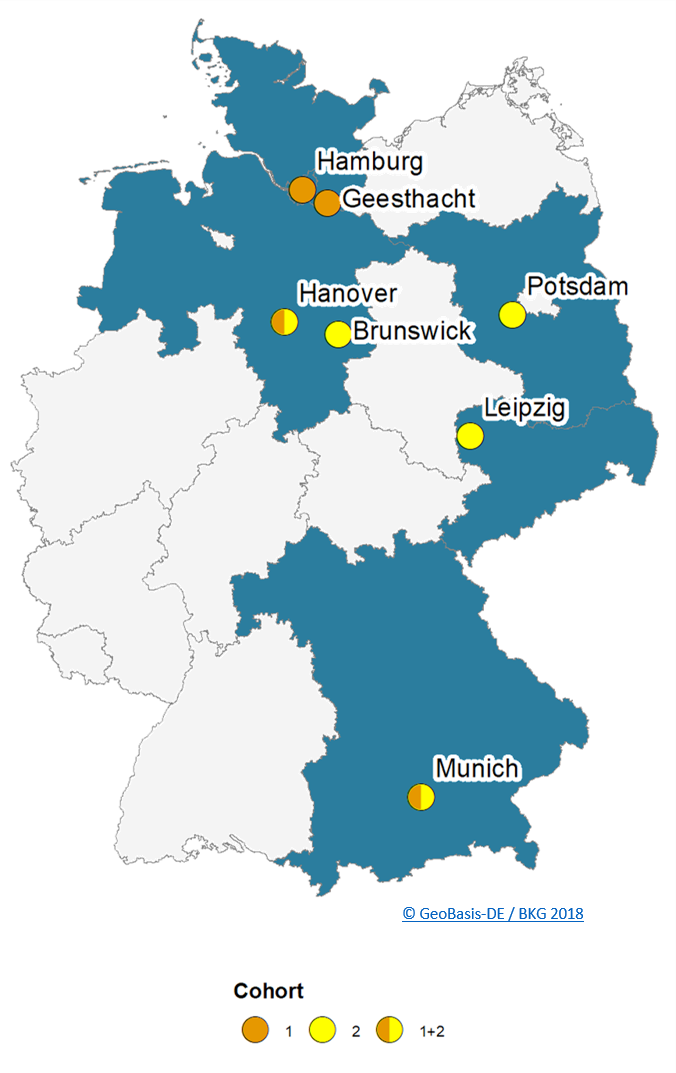
The incubators were proposed by different members of the German ESS community. The map above shows the origin of the proposoals.
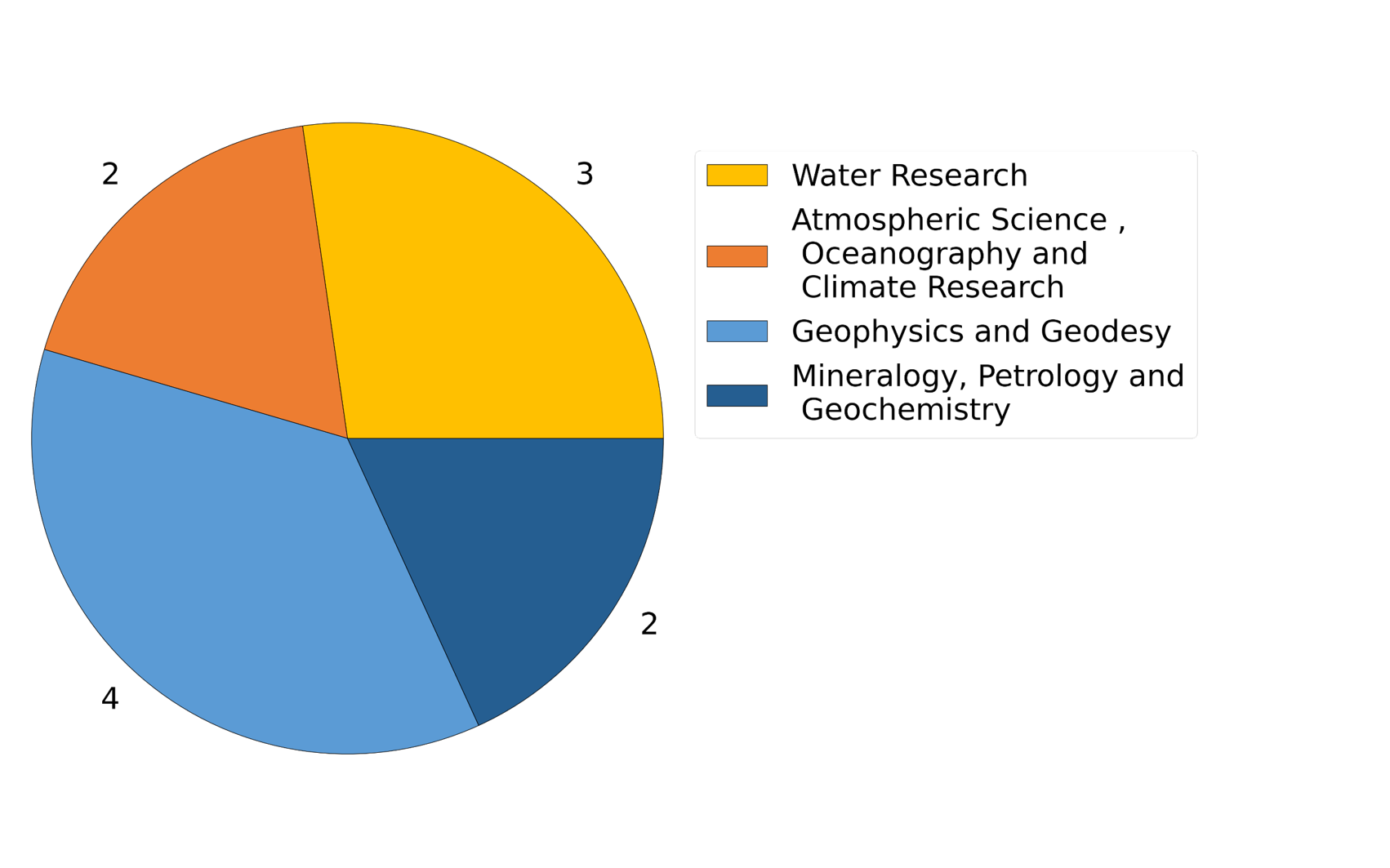
ESS related DFG topics of propsals
Domain: Geophysics
and Geodesy
Contact: Josefine
Umlauft. ScaDS.AI – Center for Scalable Data Analytics and Artificial Intelligence
Email:  josefine.umlauft@uni-leipzig.de
josefine.umlauft@uni-leipzig.de
Cooperators: Anja Neumann, Enrico Lohmann, Daniel Obraczka, Tobias Jagla. ScaDS.AI
Duration: 6 months
Sampling remotely sensed time series data for
training a Machine Learning model is not trivial due to their inherent
characteristics, such as their uneven data distribution in space and time,
auto-correlation effects for data points in close spatio-temporal vicinity and
their high data volume which needs to be handled in an efficient manner. Based
on previously developed basic Machine Learning Tools for remotely sensed data
in the form of an Earth System Data Cubes (ESDC), we will introduce and
implement a new bucket sampling strategy that accounts for the special
characteristics of geo-spatial data. We will develop and provide an open-source
software (wrapper).
Domain: Water Research
Contact: Hannes
Müller-Thomy. TU Braunschweig, LWI-Department of Hydrology and River Basin Management
Email: h.mueller-thomy@tu-braunschweig.de
Duration: 6 months
Thousands
of years of analogue records exist in earth system sciences, but are still an
unburied treasure in the age of digitization. The digitization of these data
needs manpower – but not necessarily with scientific background. Breaking down
the digitization to an easy applicable smartphone application enables the
involvement of citizen scientists to overcome the manpower bottleneck. This app
can be applicable to all kind of analogue data and hence useful for numerous scientific
fields.
Domain: Mineralogy, Petrology and Geochemistry
Contact: Artem Leichter. Institute
of Mineralogy, Leibniz University Hannover
Email:
leichter@ikg.uni-hannover.de
Cooperators: Renat Almeev and Francois Holtz, Institut of Mineralogy, Leibniz University Hannover
Duration: 6 months
A central obstacle to the widespread use of new methods (e.g., machine learning, artificial intelligence) is of a purely practical nature. Namely, the lack of practical know-how and experience in the use of relevant programming languages, frameworks and libraries. The programming landscape is so diverse that even among computer scientists, depending on the domain, the knowledge of different frameworks and programming languages is unevenly distributed, depending on the tasks at hand. For specialists from other fields (e.g., Earth Science System), for whom programming is primarily a means to an end and domain-specific content must be prioritized, the corresponding know-how for programming is even more sporadically distributed. To address this problem, we propose the use of Large Language Model (LLM) assistance systems. These systems have proven to be very successful in automatic code generation. Combined with a secure environment where automatic code can be executed directly, they allow users to become developers and significantly reduce the programming skills required.
GitLabDomain: Geophysics, Geodesy
Contact:Yu Feng. Chair of Cartography and Visual Analytics, Technical University of Munich
Email: y.feng@tum.de
Cooperators: Guohui Xiao and Liqiu Men. Norwegian University of Science and Technology and University of Bergen
Duration: 6 months
In
Earth System Science (ESS), geodata presents notable challenges due to its
diverse standards generated by different agencies or individuals, making it
difficult to access and query the data in an integrated manner. This
heterogeneity requires significant effort from researchers to access,
integrate, and effectively utilize the data. Moreover, users, especially
beginners, may often encounter difficulties when interacting with the data
through SQL or SPARQL queries. To tackle this, the project proposes utilizing
Virtual Knowledge Graphs (VKGs) and Large Language Models (LLMs) as a solution.
By leveraging VKGs and LLMs, the project aims to develop a system that enables
users to access ESS-related data through natural language queries, facilitating
integrated access and reducing the complexity of querying certain geo-entities.
The project's ultimate goal is to provide researchers in ESS with an efficient
and user-friendly approach to accessing and exploring heterogeneous geodata,
empowering them to conduct data-driven studies and gain valuable insights for
ESS research.
Domain: Water
Research
Contact: Jochen Klar. Potsdam Institute for Climate Impact Research (Leibniz)
Email:
jochen.klar@pik-potsdam.de
Duration: 6 months
The ISIMIP Repository of the ISIMIP project holds the world's largest collection of
global climate impact model data. However, both the format (NetCDF3) and file
sizes represent a major barrier for many users. We here propose to build an innovative web-based
service that allows users to extract, process and download subsets of the data. User-defined extraction, chained
processing and data interaction through scripts and interactive Jupyter
notebooks will largely widen the user base. Users can initiate processing tasks
in the cloud and download the resulting files in different formats. The code
will be released as open source software and, as the application is not tied to
ISIMIP or the ISIMIP conventions, can be adopted for similar archives of NetCDF
files.
Domain: Atmospheric Science, Oceanography and Climate Research
Contact: Marco Kulüke, Deutsches Klimarechenzentrum (DKRZ)
Email: kulueke@dkrz.de
Cooperators: Stephan Kindermann, DKRZ; Tobias Kölling, Max-Planck Institute for Meteorology.
Duration: 4 months
DOI:
10.5281/zenodo.7646356
Making data FAIR requires not only trusted repositories but also trusted workflows between data providers and infrastructure providers. Limited data access, unintentional and unnoticed data changes or even (overlooked) data loss pose great challenges to those involved. This incubator project aims to mitigate these challenges by exploring an easy-to-use data management service for researchers based on the InterPlanetary File System (IPFS), an emerging distributed web technology, which ensures data authenticity and fault-tolerant remote access. Based on a transferable prototypical implementation to be built within the DKRZ infrastructure, the suitability of the IPFS for a distributed and secure "web" for research data is being examined.
Domain: Mineralogy, Petrology and Geochemistry
Contact: Artem Leichter, Institute of Cartography and Geoinformatics, Leibniz University Hannover
Email:
leichter@ikg.uni-hannover.de
Cooperators: Renat Almeev and Francois Holtz, Institut of Mineralogy, Leibniz University Hannover
Duration: 5 months
DOI: 10.5281/zenodo.7744225
Creating training datasets for machine learning (ML) applications is always time consuming and costly. In domains where a high degree of expertise is required to generate the reference data, the corresponding costs are high and thus slow down the use of artificial intelligence (AI) systems. This proposal focusses on automated mineralogy and will provide tools to characterize the microscopic textural and mineralogical features of thin sections of rocks using back scattered electron images. Our goal is to address this problem with a data mining application where unsupervised methods in combination with expert users generate reference data without additional effort and cost for explicit labeling. The tools will be developed so that it can be used by scientists that have not a profound knowledge of ML.
Proposal GitLabDomain: Atmospheric Science, Oceanography and Climate Research
Contact: Ankita Ravi Vaswani, Institute of Carbon Cycles, Helmholtz-Zentrum Hereon
Email: vaswani.ankita@gmail.com
Cooperators: Klas Ove Möller, Institute of Carbon Cycles, Helmholtz-Zentrum Hereon
Duration: 6 months
DOI:
10.5281/zenodo.7763864
23Advances in high-throughput in situ imaging offer unprecedented insights into aquatic ecosystems by observing organisms in their natural habitats. However, unlocking this potential requires new analysis tools that transcend species identification to reveal morphological, behavioral, physiological and life-history traits. We will develop, document and validate an image analysis pipeline for semi-automated functional trait annotation, apply it to zooplankton in a continuously monitored North Sea region, and train a neural network for full automation. We foresee that these tools will enable new avenues of investigation in aquatic research, ecosystem modelling and global biogeochemical flux estimations, revealing previously inaccessible relationships between species biodiversity, zooplankton traits and seasonal variations in environmental conditions.
Domain: Geodesy, Photogrammetry, Remote Sensing, Geoinformatics, Cartography
Contact: Hao Li, Chair of Big Geospatial Data Management, Department of Aerospace and Geodesy, Technical University of Munich
Email: hao.li@uni-heidelberg.de
Cooperators: Martin Werner, Chair of Big Geospatial Data Management, Department of Aerospace and Geodesy, Technical University of Munich
Duration: 6 months
DOI: 10.5281/zenodo.7562586
Humans rely on clean water for their health, well-being, and various socio-economic activities. To ensure an accurate, up-to-date map of surface water bodies, the often heterogeneous big geodata (remote sensing, GIS, and climate data) must be jointly explored in an efficient and effective manner. In this context, a cross-platform and rock-solid data representation system is key to support advanced water-related research using cutting-edge data science technologies, like deep learning (DL) and high-performance computing (HPC). In this incubator project, we will develop a novel data representation system based on Hierarchical Data Format (HDF), which supports the integration of heterogeneous water-related big geodata and the training of state-of-the-art DL methods. The project will deliver high-quality technical guidelines together with an example water-related data repository based on HDF5 with the support of the BGD group in TUM, with which the NFDI4Earth will consistently benefit from this incubator project since the solution can serve as a blueprint for many other research fields facing the same big data challenge.